Using AWS Rekognition in CFML: Performing Facial Sentiment Analysis on an Image
Posted 5 August 2018
Facial sentiment analysis is an interesting use case for Rekognition. This process takes an image and returns a number of pre-set attributes about the faces in that image — age range, gender, eyes open/closed, smiling/not smiling, and so on, as well as the emotions of the person in the image. While more objective measures tend to be accurate in this kind of analysis, emotion analysis is still quite subjective and, in my opinion, prone to both error and significant bias.
That said, I think it’s still valuable to see how Rekognition handles this process. Some of the results can be quite useful, and the learning model is constantly retrained and improving.
Following the usual “make a request object, get a result object back” pattern in the AWS Java SDK, here’s an outline of how you perform sentiment anlysis on the faces in an image:
- Get a copy of the Rekognition client we created in the first part of this series.
- Create a “DetectFacesRequest” object.
- Create an “Image” object in the Rekognition service to work with.
- Create a “S3Object” object that specifies the path to the image on S3 that you want to treat as the image for the Image object created in step 3.
- Set the S3Object into the Image object.
- Set the Image object into the DetectFacesRequest.
- Run the DetectFacesRequest.
- Get back a DetectFacesResult object.
Again: this is Java. Everything is an object and the code is going to be a bit verbose.
The Code to Run Sentiment Analysis on Faces in an Image
Here’s how we do this in the AWSPlaybox app:
If you haven’t already read the entry on the basic setup needed to access AWS from CFML, please do so now.
As in the example of detecting labels in an image, we’re going to start the process in /rekognition.cfm by providing a list of paths to images already in S3 from which we can randomly choose:
<cfset s3images.facesForMatching = [ "images/bk-imageOne.png", "images/bk-imageTwo.jpg", "images/jk-imageOne.jpg", "images/jk-imageTwo.jpg", "images/bk-imageThree.jpg", "images/bk-imageFour.jpg" "images/jk-imageThree.jpg","images/ak-imageOne.jpg","images/ak-imageTwo.jpg"] />As before, this is just an array of paths to files on S3, nothing more. The files just need to already be on S3. The code in the AWSPlaybox app does not load them up there for you.
Later in /rekognition.cfm, we randomly select one of those images from the array and run detectSentiment() on that image. We pass in the name of the S3 bucket where the images can be found, and the string value of the path to the randomly selected image.
case 'detectSentiment':
sourceImage = s3images.facesForMatching[randRange(1, arrayLen(s3images.facesForMatching))];
detectSentimentResult = rekognitionLib.detectSentiment(s3images.awsBucketName, sourceImage);
break;Now we hop over to rekognitionLib.cfc, where the real work happens. If you read through detectSentiment(), you’ll see the eight steps listed above translated into code:
// 1. Get a copy of the Rekognition client
variables.rekognitionService = application.awsServiceFactory.createServiceObject('rekognition');
// 2. Create a "DetectFacesRequest" object.
var detectFacesRequest = CreateObject('java', 'com.amazonaws.services.rekognition.model.DetectFacesRequest').init();
// 3. Create an "Image" object in the Rekognition service to work with.
var imageToAnalyze = CreateObject('java', 'com.amazonaws.services.rekognition.model.Image').init();
// 4. Create a "S3Object" object that specifies the path to the image on S3 that you want to pass into the Image object.
var imageOnS3 = CreateObject('java', 'com.amazonaws.services.rekognition.model.S3Object').init();
imageOnS3.setBucket(arguments.awsBucketName);
imageOnS3.setName(arguments.pathToImage);
// 5. Set the S3Object into the Image object.
imageToAnalyze.setS3Object(imageOnS3);
// 6. Set the Image object into the DetectLabelsRequest.
detectFacesRequest.setImage(imageToAnalyze);
// 7. Run the DetectFacesRequest, and 8. Get back a detectFacesResult object.
var attributesArray = ["ALL"];
detectFacesRequest.setAttributes(attributesArray);
var detectFacesResult = variables.rekognitionService.detectFaces(detectFacesRequest);Note that right before we tell the rekognitionService to detectFaces(detectFacesRequest), we create an array called attributesArray with a single entry, the string “ALL”. What is this about?
By defalt the detectFaces() function in Rekognition only returns a small set of features: BoundingBox, Confidence, Pose, Quality and Landmarks. That is enough if you only want to know the pixel-based position of all the faces in the image. If you want the full analysis of each face, you have to explicitly pass in an array containing a single string (“ALL”) as the attributes for the detectFacesRequest.
So now we have a DetectFacesResult object (called detectFacesResult) that contains the analysis of faces in the image. What do we do with that?
Processing the Sentiment of Each Face in the Image
As this is Java we’re working with, the detectFaces function in Rekognition returns an array of objects of the type com.amazonaws.services.rekognition.model.FaceDetail. There will be one FaceDetail object for each face found in the image.
The FaceDetail object contains a number of properties, most of which are represented as their own individual objects. The age range of the face is actually an AgeRange object of the type com.amazonaws.services.rekognition.model.AgeRange. The has beard? property is a Beard object of the type com.amazonaws.services.rekognition.model.Beard. This is the case for almost all the properties of the FaceDetail object, except for confidence, which is an integer value representing how confident Rekognition is that this is actually a face.
In order to process the FaceDetail array, we loop over each FaceDetail (face) object. Unlike the image labels array, we can’t just loop through the labels that come back. We have to specify each property explicitly because each property is a Java object with its own methods. Here’s the code in rekognitionLib.detectSentiment():
var facesArray = detectFacesResult.getFaceDetails();
facesArray.each(function(thisFaceObj, index) {
faceCounter++;
returnArray[faceCounter] = structNew();
returnArray[faceCounter]['Age Range'] = thisFaceObj.getAgeRange().getLow() & "-" & thisFaceObj.getAgeRange().getHigh();
returnArray[faceCounter]['Gender'] = thisFaceObj.getGender().getValue();
returnArray[faceCounter]['Eyeglasses'] = thisFaceObj.getEyeglasses().getValue();
returnArray[faceCounter]['Sunglasses'] = thisFaceObj.getSunglasses().getValue();
returnArray[faceCounter]['Smiling'] = thisFaceObj.getSmile().getValue();
returnArray[faceCounter]['Eyes Open'] = thisFaceObj.getEyesOpen().getValue();
returnArray[faceCounter]['Mouth Open'] = thisFaceObj.getMouthOpen().getValue();
returnArray[faceCounter]['Has Beard'] = thisFaceObj.getBeard().getValue();The emotions property of the FaceDetail object is its own array. You never know how many emotions will be returned for a given FaceDetail (face) object. As such, we loop through the array of com.amazonaws.services.rekognition.model.Emotion objects and get the emotion label (Type) and confidence value.
var emotionsForFace = thisFaceObj.getEmotions();
var thisEmotionObj = 0;
var emotionCounter = 0;
emotionsForFace.each(function(thisEmotionObj, index) {
emotionCounter++;
returnArray[faceCounter]['emotions'][emotionCounter] = structNew();
returnArray[faceCounter]['emotions'][emotionCounter]['Type'] = thisEmotionObj.getType();
returnArray[faceCounter]['emotions'][emotionCounter]['Confidence'] = Int(thisEmotionObj.getConfidence());
});There’s probably a more compact way of pulling out each property of the FaceDetail object and converting them into a set of CFML structures, but I wanted to do this is a simple, clear way.
Displaying the Results
Back on /rekognition.cfm, we can take our CFML array of structures — one for each face in the image — and loop through it to display the results on screen:
<cfloop array="#detectSentimentResult#" index="idxThisFaceInfo">
<cfset faceCounter++>
<p>Face #faceCounter#:</p>
<cfdump var="#idxThisFaceInfo#">
</cfloop>I’m simply cfdump-ing the structure here because it’s all already nicely labeled from rekognitionLib.detectSentiment() and, honestly, it’s less code than writing out each property. :)
Here’s an example result set:
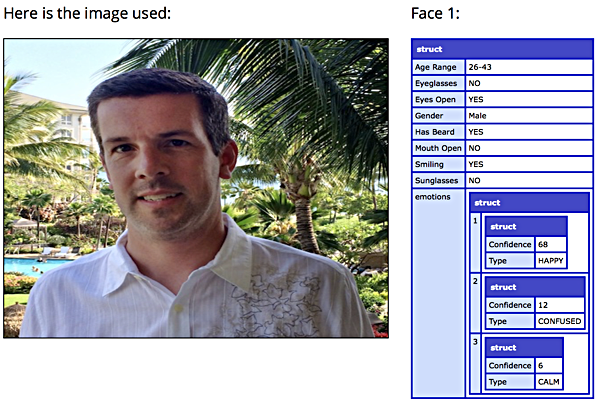
As you can see, it’s correct in all of the binary attributes (eyes open, gender, mouth open, etc) and the age range as well. It even says that I have a beard because of the scruff on my face. The emotions array shows a 68% confidence that I’m happy (I was in Hawaii, how could I not have been?), a 12% confidence that I’m confused, and a 6% confidence that I’m calm.
Here’s another example result set:
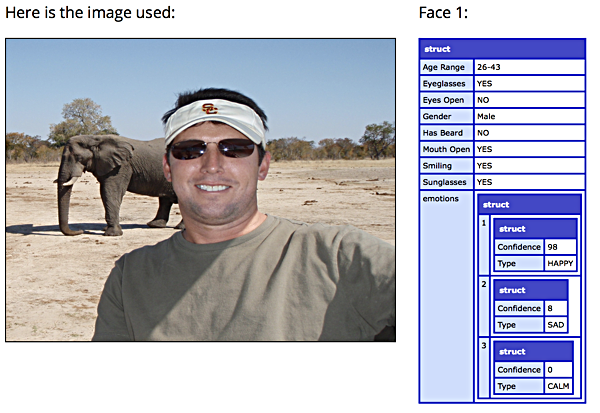
Again, Rekognition gets things like wearing sunglasses, smiling, and the mouth being open. It’s pretty sure that my brother was happy in this picture. He’s on safari, so how could you not be happy?
In this example, we displayed labels on screen. In an image search application, you’d likely want to store the emotions in the database along with the unique image identifier. If you were running a stock photos service, you’d also want to store the age range, gender, smiling, and other attributes.
Sentiment analysis in Rekognition has been promoted as a way to better engage audiences. You could use Rekognition Video and ingest a live stream of people in a store and see if they are happy, sad, or confused, and provide direct interaction based on what their perceived emotional state may be. You could also generate special offers based on their age range or gender.
If this all sounds a little invasive, it definitely is — at least to me. Facial recognition is already being used in China to capture criminals, and a similar pilot program in Orlando received significant backlash. A Chinese school has been using facial sentiment and feature detection to make sure that students are paying attention in class. You can see how easy it would be to do this using Rekognition, where you could detect if someone’s eyes were open (if not, they’re sleeping in class), and if they’re currently confused about the content of the class (based off the emotions returned in the facial analysis).
Given that most facial analysis machine learning models are still subject to significant bias, you need to tread carefully with this kind of work. It’s shockingly easy to work with services like Rekognition. We just need to understand the potential bias and error at the heart of these services.
Up next, we’ll use Rekognition to compare two faces to see if they are the same.